Language models such as ChatGPT, while powerful, have certain limitations when it comes to the volume of data they can retain during a conversation session. It’s not as simple as pasting entire books or large PDF documents into the chat window and expecting the model to answer questions about the content accurately.
In this article, we’ll tackle these limitations head-on using OpenAI embeddings. We’ll guide you through a step-by-step process to enhance ChatGPT’s capabilities within a .NET / C# program, allowing you to leverage its full potential.

Table of Contents
Extract data from documents
Here we will focus on how to extract data from PDF documents but the principle will be the same for other machine readable documents.
After creating a new .NET 7 console app, we need to add the ability to read Pdf files. We’ll use PdfPig for that task. You can simply install the nuget package:
For a first approach we’ll split the Pdf file into chunks of pages and store the page’s text together with a minimal amount of meta information (page number and file name). Depending on your needs it might be better to split by paragraphs and to store additional meta information.
Create vector embeddings for the document data
We will use the OpenAI API to create embeddings for the chunks of data we have previously extracted from our documents.
We could use OpenAIs REST interface directly, but in this tutorial I’ve chosen to use the OpenAI-API-dotnet wrapper for a little more comfort.
In either case, you’ll need to grab your OpenAI API key. For that you need to have an OpenAI Pro account.
Visit platform.openai.com/playground and click on the account icon on the top right and then choose “View API Keys” from the menu. From there you can create a new secret API key. Please take a copy of that key – we’ll need it in the next step.
Now, to download and install the OpenAI-API-dotnet package enter:
Now we can write a small helper function to get the actual vector of floating numbers for a text:
Enter the api key and do a quick test.
The result will be a fairly large array of floating numbers:
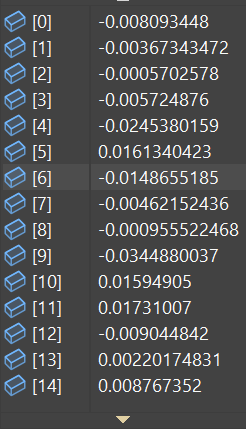
Digression: What are vector embeddings
Vector embeddings, also referred to as word embeddings, are a type of word representation that allows words with similar meaning to have a similar representation. They are a distributional representation of language that’s embedded in the high-dimensional space. Embeddings translate the high-dimensional vectors that represent words in a text into a lower-dimensional space.
Word embeddings are learned from data and capture a lot of information about words. For instance, the relationship between words can often be represented through arithmetic on the corresponding word vectors in the embedding space.
Here is a simple description of how it works: every word is represented as a vector in n-dimensional space. Words that share common contexts in the corpus are located in close proximity to one another in the space. The position of a word within the vector space is learned from text and is based on the words that surround the word when it is used. The position of a word in the learned vector space is referred to as its embedding.
There are many techniques to generate word embeddings, two of the most famous ones are Word2Vec by Google and GloVe by Stanford. Word2Vec uses shallow neural networks and is based on either the skip-gram or continuous bag of words (CBOW) model. GloVe, on the other hand, leverages matrix factorization techniques on the word-word co-occurrence matrix.
Word embeddings have been very effective in improving the performance of machine learning models in natural language processing (NLP) tasks such as sentiment analysis, named entity recognition, machine translation, and more, because they capture the semantic relationships between words in a compact form.
It’s important to note that the concept of embeddings can also be extended beyond words to represent other types of objects or concepts. For example, in recommendation systems, embeddings can be used to represent user and item characteristics. Similarly, graph embeddings represent nodes and edges in a graph, and so on. The key idea in all these cases is to represent objects in a way that captures their relationships or similarities.
Can I trust OpenAI with my documents?
This question should definitely be clarified before sharing one’s data with external companies. OpenAI is no exception.
In its current form (at the time of writing), OpenAI does not use the submitted data to train its own models or improve its own services. Details on this can be found here.
I’m no lawyer, but my gut feeling is that I would only send data to the API that is already available for free use on the internet anyway. This would include, for example, sales brochures and advertising material.
Store the vectors in a free open source vector database
Now that we know what embeddings are and how we can create them, we need a good way to store those vectors. We will use the open source Milvus vector database together with the milvus-sdk-csharp for this task.
If it were just a matter of storing data, any database or even simple text files would do. Vector databases, however, offer a decisive advantage: similarities between two vectors can be determined by a similarity search. This allows you to find all similar vectors, and thus similar texts, for any text you have converted into a vector. This is exactly what we need to quickly find relevant text passages to include in our request to ChatGPT.
Running Milvus on Windows
While Milvus is designed to run as a cloud native solution, it’s also possible to run a simple stand alone version via docker compose.
So the first thing you need to make sure is that you have docker / docker compose installed on your machine. You can do a quick check in your console with
In my case I get the output Docker Compose version v2.13.0 which seems to work fine.
You should create an empty directory (e.g., c:\milvus-docker) and download the file milvus-standalone-docker-compose.yml, saving it to this directory.
Open a console and cd into that directory. There you can type:
This brings up three containers to run all necessary services for Milvus.
Warning
Please take a look at milvus-standalone-docker-compose.yml file to get the host, port and login creadentials for the instance. In my case the relevant section looks like this:
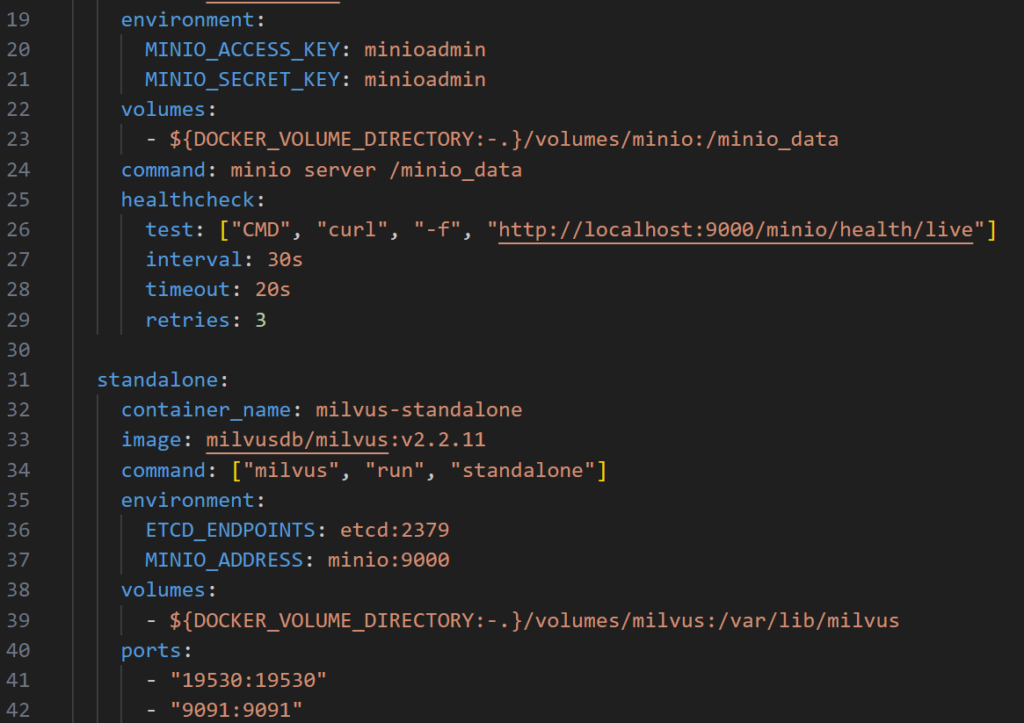
Please note the API port ist 9091 on localhost by default. The username and password is minioadmin unless you’ve changed it here.
Optional: Install milvus-insight web UI
Although this is not needed I highly recommend spinning up one more docker container with the milvus-insight web UI.
To do this write this command to your CLI:
Please note that you cannot use localhost or 127.0.0.1 as the MILVUS_URL. Use the IP address of your PC inside your LAN here. The port 19530 can also be taken from the milvus-standalone-docker-compose.yml file.
Now you can open the web UI’s URL http://localhost:8000 inside your browser:
This will open the web UI where you can check all your collection and also create queries against those.
Connect to milvus from C#
We’ll use the nuget package for milvus-sdk-c# to access the vector database.
First install the package with:
After that we can connect to the database and call a health check method to see if everything works fine:
When this returns true, we’re ready for the next step
Create a collection
Now that we have a database system we can create a table – or in milvus terms a collection. This collection will later hold all data that we have crawled from the Pdf files.
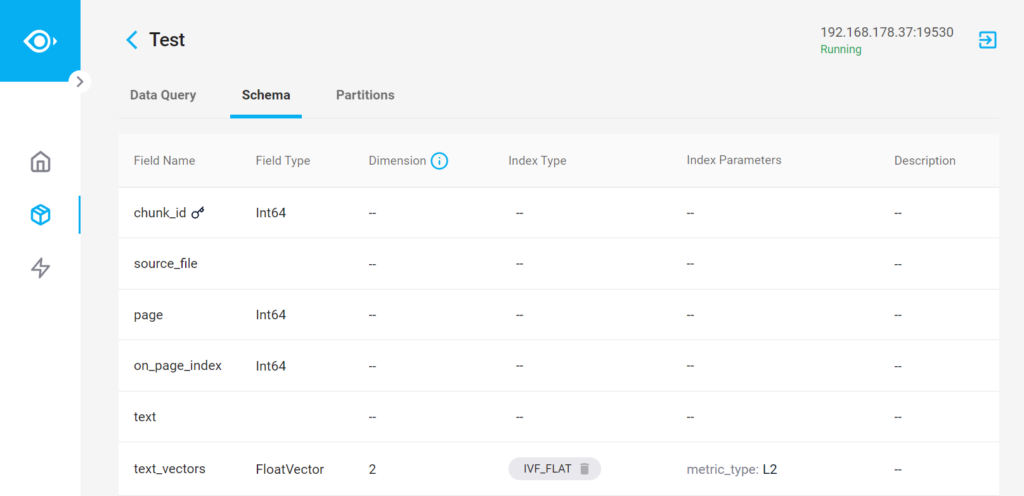
This collection resembles the Chuck class we had defined for the documents’ text chunks. There are two additional fields chuck_id and text_vectors.
The text_vectors field is where we can store the vectors that we need to retrieve in the next step. It is important to set the dimension count correctly. When using the OpenAI embeddings we are getting back arrays of 1536 floats.
We’ve also created an in-memory index for for the text_vectors field to speed up the search process.
Store the data
It might be clearer to say “Because Milvus is optimized for large datasets, we need to convert our chunks into data arrays before we can call the insert method.
The method could look something like this:
Please note the for real world scenarios you have take care of the maximum tokens that the embedding model can handle. Since we are using the text-embedding-ada-002 model in this example, the maximum input size is 8191 tokens. You can think of a token as the most common part of a word. Many short and common words take one token, but there are many words the need more than one token.
You can check OpenAI’s tokenizer for an exact number.
Everything in one method
I’m sure you can figure this out by yourself but for completeness, here’s the method I created that combines all tasks that are needed to digest a PDF file and store it together with the embeddings into the database:
Use the stored vectors to answer user questions
This is where the magic happens! In order to use the vectors together with ChatGPT we can use the following trick: First we need to convert the user’s question to a vector just as we did with the chunks of document data before. With that question vector we can query our vector database to find relevant information from our documents. We can then feed that information as starting promt into a new chat conversation followed by the original user question and hand it over to OpenAIs completion model. ChatGPT will then incorporate the knowladge when creating an answer for the user.
Create embedding for the question
When the user prompts our system, the first thing we need to do is a similarity search for the prompt text.
To do that we need to convert the prompt into a vector first.
For my tests I started with a freely available copy of “Learn English through story – Robinson Crusoe”. If you want to follow you can download a copy of that eBook here. This eBook is probably not the best choice, because I’m sure that ChatGPT will know everything about Robinson Crusoe without any additional help. In reality you will have some more specialized documents.
One question I’m really excited about is “What did Robinson Crusoe used to build some furniture?” Let’s convert the text into vectors:
Query the vector database
With those vectors we can now query our database for the top 3 closest matches
The FindChunksAsync() Method is still a little ruff – surely we can refacture this for a shorter outcome:
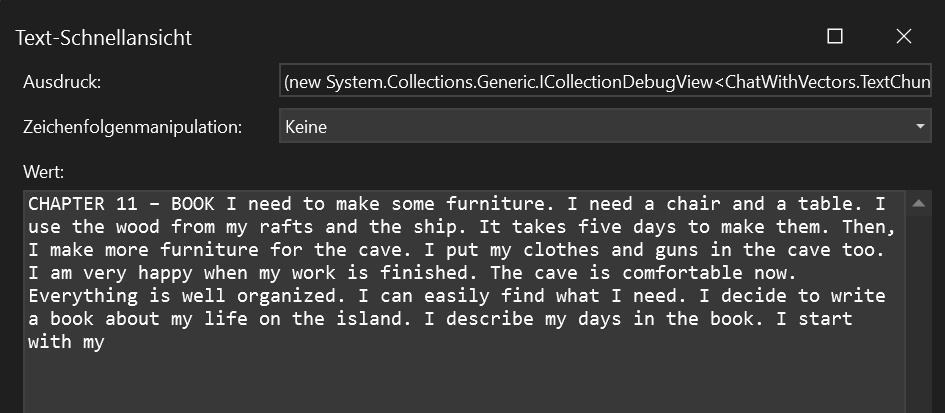
Nevertheless it works as expected. We get a very good match from our test document on page 22:
Asking ChatGPT with context from the book
The rest should be smooth sailing. The idea is to prepare a new prompt for ChatGPT that includes the original question together with the text snipped we fetched from our database. Maybe something like this can get some good results:
What did Robinson Crusoe used to build some furniture?
Take the following information into account when answering the question:
Text snippet 1
Text snippet 2
Text snippet 3
The method could look something like this:
I’m sure you can up with much better ways to formulate the prompt but for the first shot, the result was already quite good.
ChatGPT (3.5) answered with “use the wood from his rafts and the ship to build some furniture.”
I’m sure that by tweaking the promt and using ChatGPT 4.0 the answer will be even better.
Conclusion
While there’s a lot of tweaking to be done to achieve the best possible results, the method described here is definitely a viable solution for overcoming ChatGPT’s limited context size when working with large knowledge bases.
At soft-evolution, we’re not just observing the advancements in AI and machine learning – we’re actively participating in them. We’re constantly exploring, experimenting, and refining our methods to leverage the full potential of tools like OpenAI and Milvus. Our goal is to harness these powerful technologies to create innovative solutions that meet our customers’ unique needs.
We’re currently deep in the process of fine-tuning and optimizing the approach outlined in this article, and we’re excited about the possibilities it opens up. By enhancing ChatGPT’s capabilities with OpenAI embeddings and vector databases, we’re pushing the boundaries of what’s possible in AI-assisted interactions.
We believe in the power of collaboration and shared knowledge. If you have any insights, comments, or questions about this topic, we’d love to hear from you. Similarly, if you’re facing challenges in this area and could use some support, don’t hesitate to reach out. We’re here to help, and we’re eager to learn and grow together in this fascinating field.


Pingback: In-Memory Vector Search with C#: A Practical Approach for Small Datasets - crispycode.net
Hi Alexander,
Another great post, you are using OpenAI to generate the vectors. OpenAI needs a key, is there another open source like OpenAI that does not need the use of a key.
Thanks
Jason
Hi Jason,
there’s a page on Huggingface deticated to comparing many embedding models: https://huggingface.co/spaces/mteb/leaderboard. Many of the models are free and open source.
You may want to sort the list by retrieval average in descending order and the choose a model that offers a good compromise between performance and size.